Monitoring the Example Microservices
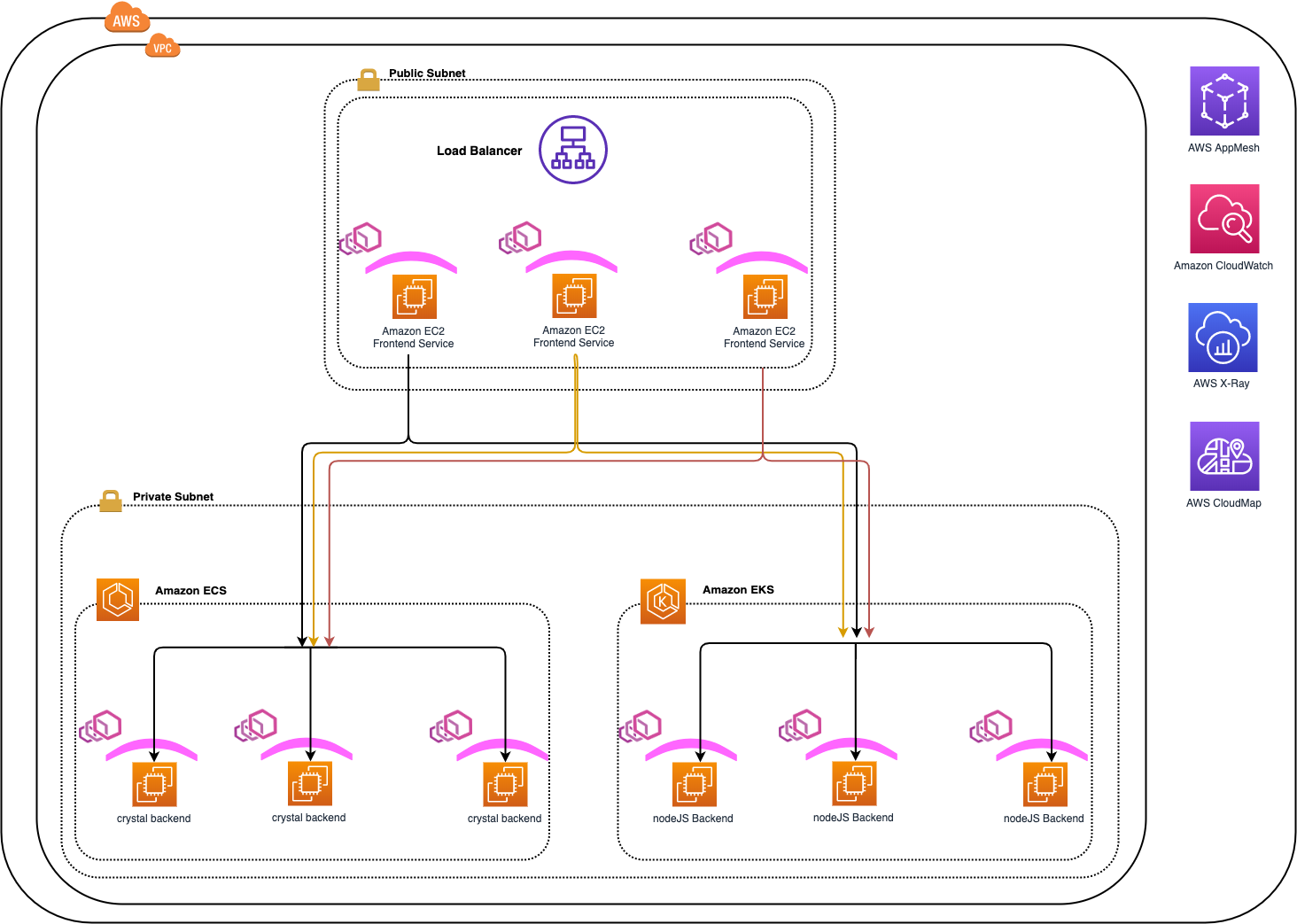
Planning to handling transient faults is a common practice in a microservices architecture. Retry of a request can help overcome short lived network blips or short term interruptions on the server services due to redeployments like Service Unavailable (HTTP Error code 503), Gateway Timeout (HTTP Error code 504).
Since our application makes recurring use of network calls to other services, we will add the ability to retry connections between services using AWS App Mesh based on HTTP error codes.
Let’s see how we can set retry duration and attempts within route configurations. Currently, when a request is made, our frontend Ruby service creates a header to denote the current time and send that request to the Crystal backend service.
In this chapter, the first thing we will do is to change the Crystal backend application code so the backend application will start sending 503 responses to some of the Frontend requests if the time of the original request (passed through the header) and the current time is less than 1 second.
Initially without retry in place this error will be thrown consistently. After we introduce retries, we will begin to see the time of the original request and the current time will eventually be greater than 1 second (depending on the retry policy configuration you want to set but the example configuration will work once the route is updated during the walkthrough). At this point the Crystal backend service will return a 200 and send back the response.
Follow these steps to implement the error responses in the Crystal backend application and the Retry logic in App Mesh: